综述:
本周是2018年华中科技大学同学来休斯顿大学ECE学院进行暑期实习的第八周。在导师们和学长学姐们的指导和带领下,大家的科研项目也都在有条不紊的开展着,期间有课题进展的喜悦,也有实验不顺的苦恼。相信大家可以克服困难,努力前行。
个人实习日志:
UH实习日志|赵隽逸
本周的实验又有了新的进展,按照老师的指导,我们尝试了线性激光照射磁流体,实验现象与预期基本一致。光线可以像一把铡刀一样将磁流体劈开。我们希望能够设计一套setup将该现象运用到实际当中,这样才能真正发挥科研的价值。而这其实也正是当今科研工作者所面临的问题之一,高校科研与工业界脱节严重,很多科研成果都是实验室界别的,无法应用到工业界当中。而对于科研工作者和科学家来说,他们的终结目标就是用自己的科研成果来改善世界,造福全人类,而非单纯的为了文章而科研。然而现在很多的科研工作者并没有意识到这一点,科研俨然变成了一种文章竞赛,至于具有多大的应用价值完全不去关心。
另外本周末是中秋节。为了庆祝中秋节,我们周日一起去到师兄家开了个火锅party,晚上又去了老板家。老板家的昙花正好盛开,正所谓昙花一现,第一此见到盛开的昙花,实际的绽放时间也就3个小时。师母为我们做了月饼,还有从家门口湖里打上来的鱼。老板家是一个2层的house,很是气派,据说在德州买这样一套house也并不是很贵,可能这样的价格在国内连一个apartment都买不起,因为美国人并不炒房,并不会把买房子作为一种投资赚钱的方式,这与国内是有巨大差别的

UH实习日志|李宛泽
仔细想想,这已经是到这里的第九周了,实习可以说已经过去了三分之二,再过一个月就要离开了。可以说有点不舍,也有些着急。今天主要还是改了改之前的方案,由于实验室的打印机存在误差,我只能一点一点地调整尺寸进行配合。另外,今天我试着使用了示波器,将fishfinder传感器的输入信号显示出来,但是效果并不理想,完全看不出什么来。实验室的法国学长答应明天帮我看看。
周二Becker教授和我们进行了之前打碎钢化玻璃杯的实验。我原本是想尽量模拟出传感在水中的状态,在贴近真实工作环境的情况下进行实验,因此该实验一直没有进行,但是Becker教授直接用金刚钻把被子打透了,最后杯子虽然成功地碎掉了,但是这个过程的困难程度还是超出了我的想象,因此不得不放弃了这个方案。晚上,和实验室学长前往附近的河边测试了设备,我们利用两个三角架和滑轮搭起了一条横跨整条河的绳子,然后将传感器挂在绳子上,从河的一侧拉到另一侧,记录数据。但是由于将绳子从一侧拉到另一侧的操作比较复杂而且在测试途中绳子经常缠在一起,再加之去的比较晚,因此并没有完成预计的测试任务。
另外周二我在实验室学长的帮助下将fishfinder传感器的波形调了出来,但是进一步如何测试还没有想法。
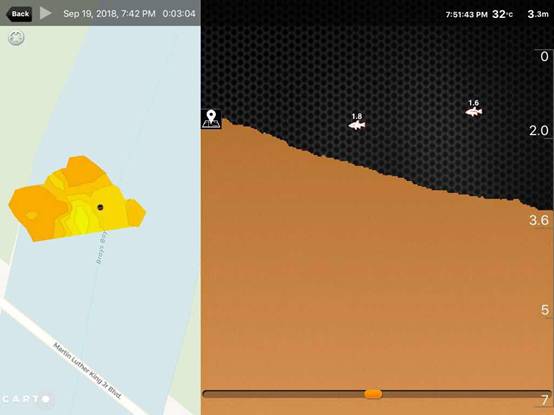
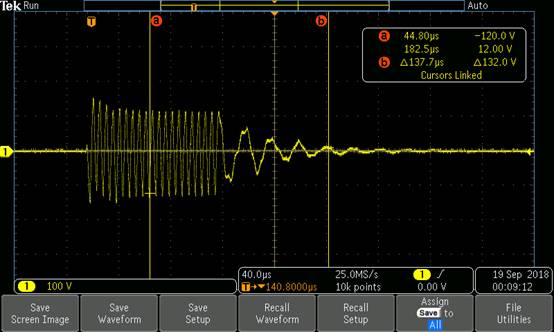
本周接下来的时间里,我将主要的精力投入到了整体式外壳的研制当中。并做了一些实验,然而效果并不十分理想,原本希望能够崩成碎片的外壳只分成了两片,经过分析,原因可能是这几条:1,由于零件采用3D打印制作,层层堆积,存在纵向和横向屈服极限不同的状况,2,实验采用的是从外面泵入空气,这样的话零件的内压就会逐渐上升直至将外壳最薄弱处击破,此处一旦被击破,气压立即下降,自然无法碎成碎片。可以考虑在内部加一层更强劲的内胆。在这个过程当中我也体验到了开发一个新产品的无奈。实验室里主要的加工途径就是3D打印,但是由于3D打印本身的性质,导致零件的水密性,气密性较差,而且还存在各向异性的问题。另外,实验室的3D打印机精度不高,若想进行螺纹配合的话要进行多次测试才能成功。然而,若是采用其他的加工方式则要耗时良久,因此也只能硬着头皮继续了。
UH实习日志|关晨宇
离回国还有不足一个月了。
本周做的工作和之前接手的两个项目都无关,原因在于前两者都陷入了停滞状态。铅沉积的实验因为发现了一些有趣的现象被教授暂时停止,他想从重新考虑实验机理并重新设计实验。Cu在wafer上沉积的实验自从上周样品送到了lam公司检测审核之后也一直没有消息,我多次询问印度小哥关于tem的进展时他都对此摇摇头并表示无奈。
但实验总是要继续的。印度小哥因此带我转战另外一个课题,这是他在硕士阶段从事的工作的一部分。虽然之前的工作已经整理完成并发表论文,但他似乎对这篇论文并非十分满意,只是因为要毕业答辩的原因才匆匆交了一个半成品。如今正好逮着机会去探索一下论文之外另外一个idea。坦白讲,初次听到这个故事时心里还时很佩服这种科研精神的。
但这样的理想主义很快被现实击败了。因为考虑到要设计探索新的实验,我们打算重新设计之前的装备。于是编软件到改电路的工作都被提上了日程。我负责的是labview软件部分的设计修改,正好借机感受了一把这个算是另类的编程软件。它采用的更像是初学编程时用的流程框图而非英文代码,因此在编程的过程中可以更加直观地看到每一段之间的相互联系,自然上手起来也就更容易一些了。印度小哥负责重新设计并焊电路,这里我倒是挺疑惑他一个同样学高分子工程的人怎么做起电路工作来也是如信手拈来一般简单,可能这是印式教育学习欧美教育的一个成功案例?
整个装置的重新设计工作在周四完成,还好留给我们两天的时间来运行设备(为了科研这小哥毅然放弃了周六的节假日,当然同样为科研献身的还有实习生我)。不过两天时间运行的三个实验里失败了两次,原因总还是装置不太稳定,装置成功开车后竟然在正常运行阶段状况百出,这是我们没曾想到的事情。但乐观一点讲,总归是得了一组数据呢。
祝下周好运吧!

贴张成果图吧~
UH实习日志|梁子云
这一周中,我们的任务任然是对医疗图片进行预处理.图像库得图片数量巨大,内容繁杂.我们采用坐标法将病变的位置标了出来.又在外面加上了限定框准确的找出病变位置.
下面是针对该图像库的一些想法和实践.
Classifying Chest X-Rays Using Deep Learning
Background
In October 2017, the National Institute of Health open sourced 112,000+ images of chest chest x-rays. Now known as ChestXray14, this dataset was opened in order to allow clinicians to make better diagnostic decisions for patients with various lung diseases.
Objective
· Train a convolutional neural network to detect and classify diagnoses of patients.
· Couple structured and unstructured datasets together into a dual classifier.
Dataset
The ChestXray14 dataset consists of both images and structured data.
The image dataset consists of 112,000+ images, which consist of 30,000 patients. Some patients have multiple scans, which will be taken into consideration. All images are originally 1024 x 1024 pixels.
Due to data sourcing & corruption issues, my image dataset consists of 10,000 of the original 112,000 images. All data is used for the structured model.
Additionally, structured data is also given to us for each image. This dataset includes features such as age, number of follow up visits, AP vs PA scan, and the patient gender.
Exploratory Data Analysis
When researching the labels, there are 709 original, unique categories present. On further examination, the labels are hierarchical. For example, some labels are only "Emphysema", while others are "Emphysema | Cardiac Issues".
The average age is 58 years old. However, about 400 patients are labeled as months, 1 of them is labeled in days.
Pipeline
Two pipelines were created for each dataset. Each script is labeled as either "Structured" or "CNN", which indicates which data pipeline the script is part of.
Description |
Script |
Model |
EDA |
eda.py |
Structured |
Resize Images |
resize_images.py |
CNN |
Reconcile Labels |
reconcile_labels.py |
CNN |
Convert Images to Arrays |
image_to_array.py |
CNN |
CNN Model |
cnn.py |
CNN |
Structured Data Model |
model.py |
Structured |
Preprocessing
First, the labels were changed to reflect single categories, as opposed to the hierarchical categorical labels in the original data set. This reduces the number of categories from 709 to 15 categories. The label reduction takes its queue from the Stanford data scientists, who reduced the labels in the same way.
Irrelevant columns were also removed. These columns either had zero variance, or provided minimal information on the patient diagnosis.
Finally, anyone whose age was given in months (M) or days (D) was removed. The amount of data removed is minimal, and does not affect the analysis.
Model (Structured Data)
The structured data is trained using a gradient boosted classifier. The random forest classifier was also used. When comparing the results, both were nearly equal. The GBM classifier was used due to its speed over the random forest, and due to producing equal or better results to the random forest.
Results (Structured Data)
Measurement |
Score |
Model |
H2O Gradient Boosting Estimator |
Log Loss |
1.670 |
MSE |
0.510 |
RMSE |
0.714 |
R^2 |
0.967 |
Mean Per-Class Error |
0.933 |
Model (Convolutional Neural Network)
The CNN was trained using Keras, with the TensorFlow backend.
The model is similar to the VGG architectures; 2 to 3 convolution layers are used in each set of layers, followed by a pooling layer.
Dropout is used in the fully connected layers only, which slightly improved the results.
Results (Convolutional Neural Network)
Measurement |
Score |
Accuracy |
0.5456 |
Precision |
0.306 |
Recall |
0.553 |
F1 |
0.394 |
Explanations
Per the blog post from Luke Oakden-Rayner, there are multiple problems with this dataset. The most notable are the images (and structured data) being labeled incorrectly. He also notes the annotators did not look at the images.
This became evident when training both models. Despite regularization, and rectifying the class imbalances, both models learned to return meaningless predictions. Per the above statement, this can be attributed to the incorrect labeling of the images.
Due to these findings, per Mr. Oakden-Rayner, and my own analysis: "I believe the ChestXray14 dataset, as it exists now, is not fit for training medical AI systems to do diagnostic work."
This doesn't discount convolutional neural networks from being able to predict diseases, but this is dependent on the labels being correct and accurate. Once this becomes rectified, and the images are correctly labeled, further analysis can resume against the ChestXray14 dataset.
在这周的空余时间中 ,我们去了休斯顿博物馆.看到了栩栩如生的玛雅文明和古埃及文化遗留下来的珍贵文物.也看到了很多恐龙及化石等.


UH实习日志|熊雨琴
新的一周,老师上周去国外开了四天的会议,所以我就将上周处理过的、有标签的图片根据分类把它们放入不同的文件夹,并且读取成hf5文件。这样之后,我建立好模型之后,可以直接将数据喂入模型里,并且用来计算loss的也是同样shape的数据。
但是,这周我的进度非常缓慢,一个原因是数据集实在是太大,另外是数据的分类移动操作很繁复。第一个原因直接造成的影响是电脑的内存出现了告急,垃圾箱的东西删除不了,电脑出现了死机状态,这个状况浪费了我很多时间,也消耗了我许多耐心。第二个状况主要是我自己造成的,在写好脚本后没有认真检查并调试,主要是没有好好了解数据库。所以当数据出现了出乎我意料之外的形式后,程序意外中断,图片的移动也中断。这直接就造成了非常糟糕的局面,一部分的图片已经抽出来了,但还剩了另一部分还留在那里。最后,我只能用笨办法,把已经抽出来的图片放回去,再用改写好的程序运行。但是,最终我还是成功的把图片预处理了,下周就可以直接训练模型了。
这周,星期五在实验室作报告的是隔壁实验室的学生,讲解的论文是一种计算近似分布的算法,也可用作一种解码器。
下面是比较直观的示例:
图中z通过p函数得到了x就是左图的分散分布,然后我们想得到的是q函数使得x能够得到z。这就是一个解码过程。然后,文章里也介绍了应用该算法能得到的结果。
下图是把mnist数据进行数据的转换的结果

UH实习日志|李昌
本周是来到休斯顿的第9周,本周在原有工作的基础上,继续对Li2DHBQ进行改性的工作。
在实验方面,本周的工作是和一位博士生师兄一起继续对Li2DHBQ进行改性研究。我们在上周提高了Li2DHBQ的容量的基础上,希望提高其循环稳定性和能量密度。我们做的主要工作还是从电极的制作和电池的安装方面入手,对每一个细节进行把控。比较遗憾的是,虽然有的电池测试出了,相比之前有了一定提高,但仍然无法达到我的要求。而大部分电池却几乎没有任何提高。这种情况也是我之前经常碰到的,即使在一个实验中改变一些变量,也无法得到不同的结果和数据。这个过程需要不断的尝试和分析。希望这最后的一个月中顺利达到我们的目标。
本周另外就是参加了一个seminar,主讲人是锂电的传奇人物,LiCoO2的发明人John B. Goodenough老先生,我的导师和另一位物理学院的大牛两人在seminar那天从UT-Austin开车把老人家接过来的。大师就是大师!开场前就很高兴的和每一个想和他合影的年轻人合影。整个speech过程也是中气十足!看得出来老人家身体还是很不错的。我自己全程聚精会神的听报告,最后鼓起勇气提了一个问题,老先生很高兴的提出了他的看法,并对我给予鼓励!这次seminar对我来说可能是另一个起点!

下周五就是自己暑期的总结汇报了,虽然组里基本都是中国人,但需要用英文做speech。希望自己能顺利的完成!
UH实习日志|张紫荆
本周是来到休斯顿的第九周,周一首先向实验室的姚教授做了weekly report,报告最近的实验进展。但是在自己整理自己的数据的过程中,就能发现其实自己那一部分的实验内容做得还并不完善。这两周我主要是在完成AQ和PTO的电导率测试这一部分的内容。我怀疑放电过程中有其他惰性物质产生,但是产生的惰性物质并不可逆,并且,由我们的加载方式测试电导率其主要决定因素为中间活物的质量。由于我觉得得出结论和汇报这一环节实验数据已经可以看出趋势,所以当时汇报报告的时候没有进一步处理数据,但姚老师对我的汇报不是十分满意,建议我要将数据进行进一步的处理,这样才可以比较严密地佐证我的观点。我也接受了姚教授的建议,决定在下一次周报的时候花更多时间来对已有的数据经行分析,而不是将过多时间用于做实验上。
在这个星期我还和国内的小伙伴做了一次有趣的互动,因为材料学院在本周进行奖学金的评选,而辅导员说支持视频答辩的方式,于是我自己在公寓录制了一个奖学金答辩的视频,发回国内,在班内答辩的现场由班长组织同学们一起观看,就想我还在现场一样。最后我也是由同学们投票获得了科创奖学金。已经快三个月没有见到班里的同学,十分想念大家,现在保研的同学也已经有了着落,找工作和考研的同学还在奋斗当中,我在这里也算和大家并肩作战,一起努力。
本周我花费了大量的时间来准备GRE的考试,在这个过程当中背单词,练习阅读和作文,分配好时间和做好学习计划都十分重要。从心态上,我认为把GRE不单单看做一次考试,看作一次对于英语能力的提升这是一种比较健康积极的态度,这样才不会过分纠结于考试的结果。最后预祝我GRE考试一切顺利~

 华中大启明学院
华中大启明学院
 创新创业华中大
创新创业华中大
 华中大创客空间
华中大创客空间