华中大-2017伯克利交流之旅(7)
作者: 发布时间:2017-08-21 点击率:122 编辑:文芳
伯克利暑期学术课程日志(8月7日)
今天的课程由一次lecture和一次seminar组成。上午的lecture主题是The Chemistry and Applications of Metal-Organic Frameworks,MOF(金属有机物骨架化合物)其实是一种与清洁能源、环境科技相关的新材料,由Kyle E. Cordova博士主讲,下午的seminar主题是Robotic, Yesterday, Today, & Tomorrow,由Xu zuo博士主讲。当然,除了两次课程之外,今天还发生了许多十分有意义的事。
上午,我们组随队7点40从酒店坐大巴出发前往伯克利分校。下车后有趣的是我们发现今天大多数人走向教室的步伐变得很快,可能是因为大家都想抢占前排学习吧,这几天大家真真切切地被伯克利学习氛围给感染了,对学习的热情变得愈发强烈。上午的课程是一节十分有趣的化学课,Kyle E.Cordova博士的讲课风格是活泼轻松的,他是在Berkeley Global Science Institute参与化学研究的一名伯克利博士。
图1 kyle E.Cordova在讲课
Kyle E. Cordova博士所理解的全球科学模式由导师、学生、研究机构等组成。这一模式的最终目标是建立一个可持续的循环,这个循环是学者积累知识成为导师,然后将他们的知识转移到其他新兴的学者身上。
图2 全球科学模式
随后,他开始讲解第一部分——MOF的化学构成。在他看来,所有的化学结构都由Joints和Linkers组成,MOF也是如此。
图3 MOF-177
图中的Zn4O(CO2)6是Joints,加上Ditopic Linker,再进行扩展便能根据扩展程度形成MOF-5、MOF-10、MOF-20。图中的黄色球部分便是可以容纳材料的空间,也就是pore。同理,不同的Joints,不同的linkers都将导致不同的化学结构与不同的容纳空间,便能通过结构实现不同的功能。而且,Pore Metrics可以很容易地被扩展下图是MOFs孔径的世界最纪录。
图4 World Record for the Largest Pore Apertures in MOFs

图5 TEM下观察的MOF
上图是在TEM中观察的IRMOF-74-VII (TEM是透射电子显微镜),可以看出上面确实存在许多小孔。另外,没有限制的小孔会有超高的表面积,一克的MOF就能达到10000m2,相当于一个足球场。
图6 MOFs超高表面积的历史发展
上图是MOFs的表面积的不断突破,其中就有中国科学家的贡献,Kyle E. Cordova博士的研究目前达到的第二高,而且他说不就后还会有他们还会有新的突破。
接下来是第二部分,主要是讲MOFs的应用。
图7 MOFs在碳循环中的作用
我们可以从图中看出,MOFs可用于二氧化碳的存储与捕获,MOFs的二氧化碳储存能显著增加运输的储存能力,MOFs捕获二氧化碳的过程中可以从源点中选择性地清除二氧化碳, MOFs的结构特征对于增加二氧化碳的捕获同样是很重要的。
图8 MOFs在潮湿的环境下选择性捕获二氧化塔
从图中可以看出,在潮湿的环境下,MOFs同样可以很好地捕获CO2. MOFs同样可以利用太阳能量对二氧化碳进行降解,还可以作为选择性二氧化碳捕获和再使用的吸附剂。老师举了现实运用MOFs的一个实例,那便是MOF-filled Fuel Tank。MOFs同样可以用于吸附大量的氢用作燃料。可以说,MOFs可以应用于清洁能源相关的很多方面。
图9 MOF-filled Fuel Tank
而且可以用于饮用水资源的运输,据老师说,MOFs的主要优点是可以存储大量的气体,且需要更少的压力。但它也有缺点,就是linkers和Joints不能够完美的匹配。
Kyle E.Cordova博士深入浅出的讲解让我们初次系统地了解了MOFs的原理、方法、应用等,可谓受益匪浅,对前沿科技的了解再一次激发了同学们学习的热情。
下午Xu zhuo博士为我们讲述了有关机器人的知识,许卓博士来自清华大学,现在伯克利读Phd。他首先提到,机器人的历史始于周朝,一个叫偃师的人按照周穆王的样子制作了一个可以站立、坐下和操纵手臂的机器人。机器人的工业化已经很成熟了,世界第一大机器人公司fanuc每年可以生产400000台机器人。再比如现今机器人的技术应用也有很多了,例如中国的大疆无人机,伯克利正在研发的无人驾驶汽车,震惊人类的围棋高手alphago等等。
图10 xu zhuo博士在讲课
许卓博士主要从两方面来讲述了机器人:第一个是运动规划,其运用情景是操纵机器人做出反应,方法是通过一系列算法来实现,如Dijkstra’s算法、RRT算法,有以下三个需要考虑的方面:1、通过高斯模型记录轨迹特性来推理下一步动作 2、使用AND-OR图(AOG)来构造复杂策略模型 3、机器人做出这个动作的安全性,即是否安全。另一个应用场景是自动驾驶汽车,以安全为约束条件,运行RRT算法,更进一步的改进可以用模型预测来控制。
第二部分讲的是现在很火的深度学习和深度强化学习,深度学习是通过深度神经网络来实现的。深度神经网络,简单的来讲就是将采集到的信息(如图像里的像素)转化成矩阵的形式,输入到第一层,第一层采用卷积算法,第二层采用样本采用,第三层再采用卷积……这样经过几层后可以将一个例如32*32的图像输出为一个10*1的向量,在通过若干次训练这个网络以后,我们通过这个输出的向量机器人可以判断出所看到的景象。
图11 深度学习
在深度神经网络的研究路程上,vondrick等人运用深度回归网络的训练大量视觉数据来预测视觉表现。它们通过训练k网络,并交替更新参数和网络选择来加强预测的多模型性质。这个交替更新参数的方法,举个例子:例如step time 1我们有一副图像输入,那么我们可以通过它来预测后20s的动作来更新网络参数,经过1s后到了step time2,我们又取了一幅图像输入,那么这幅图像又预测后20s的动作来更新网络参数,又经过1s到了step time 3,我们还是取一幅图像作为输入,预测这以后20s的动作来更新网络参数,以此类推,通过这样的交替更新网络参数的方法,我们最终可以增强机器人对于所看到的景象的判断的准确性。
后来多纳休等人又提出了一个长期的递归卷积网络(lrcn)任务识别。这个网络是“加倍深刻”的(即它也可以增加对于所看到景象的判断的准确性),因为它可以学习空间和时间上的成分表示。
后面许卓博士通过视频为我们演示了一个意图推理任务,下面是这个任务的处理每个视频帧的网络。
图12 意图推理
通过图像我们可以发现在大概400个time step以后,这个深度神经网络已经可以明显判断出视频中人类的意图是plan11了。
图13 意图推理判断
在这之中还有一个小技术,那就是提前训练,使用提前训练模式大大加快了学习过程中的学习迁移,如下图,需要训练的仅仅是后面的一部分,前面的一部分早已训练好,是一个通用模型,那么我们所花的训练时间会大大减少,这也是训练这种深度神经网络中的一个小技巧。
图14 提前训练技术
最后,许卓博士向我们介绍了深度强化学习,机器人在每种state下有一个输入,包括相应的reward,对于这个输入有一个反应,即action,这个动作作用到环境中,环境又会产生相应的state和reward(反馈),再将这个新的state与reward输入,又可以产生新的action,这就是深度强化学习的概念。反馈的公式如下:
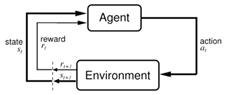
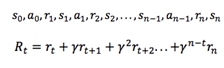
图15 反馈公式
深度强化学习采用了Q learning算法,其中的Q值就是在一个状态下执行一个操作时所产生的最大未来反馈。除此之外,深度强化学习还采用了policy gradient算法来减小误差,亦或是可以采用A3C算法,好像许卓博士最近也在研究这个A3C算法。这堂课,不论是从机器人还是深度学习的角度来说都让我们受益匪浅。
图16 Q learning 算法
今天的课程学习了许许多多关于前沿科技的知识点,这也正是我们小组来到伯克利分校参观学习的初衷,便是了解更多关于前沿科技的信息,以确定今后研究的方向,相信整个夏令营下来,我们都能清楚自己对于前沿科技的理解。
编辑:王子涵(材料15级)
作者:房莉(电气14级)、王子涵(材料15级)、王勇杰(航空16级)、张化昀(电信14级)、孙翔宇(电信14级)

 华中大启明学院
华中大启明学院
 创新创业华中大
创新创业华中大
 华中大创客空间
华中大创客空间